[혼공단] 혼공R이 5주차 미션 - Chapter 5. 데이터 가공하기. 파이프 연산자, reshape2 패키지, dcast() 함수
이번 주 스터디 내용 요약
지난 주에는 기본적인 데이터 다루기 기술들을 익혀보았습니다. 데이터를 수집하는 다양한 방법, 내장 데이터 사용하기, 평균, 중앙값, 최솟값, 최댓값, 분위수, 분산, 표준편차, 첨도와 왜도, 빈도 같은 기술적 통계량에 대해서도 알아보았습니다. 마지막으로 상자그림, 막대그래프, 히스토그램, 파이차트, 줄기 잎 그림, 산점도 등 다양한 종류의 그래프를 그려보았습니다.
[혼공단] 혼공R이 4주차 미션 - Chapter 4. 데이터 다루기. (feat. 혼자 공부하는 R 데이터분석)
[혼공단] 혼공R이 4주차 미션 - Chapter 4. 데이터 다루기. (feat. 혼자 공부하는 R 데이터분석)
[혼공단] 혼공R이 4주차 미션 - Chapter 4. 데이터 다루기. (feat. 혼자 공부하는 R 데이터분석) 이번 주 스터디 내용 요약 지난 주에는 R의 기초 문법(변수와 함수, 연산자, 조건문, 반복문 등)
it4edu.tistory.com
이번 주에는 수집한 데이터를 필요에 맞게 가공하는 방법을 공부해보았습니다.
dplyr 패키지에 포함되어 있는 기본적인 함수들을 이용하여 데이터를 정리하는 연습을 했습니다.
| 함수 | 기능 |
| filter() | 조건에 맞는 행을 추출합니다. |
| select() | 변수(열)을 추출합니다. |
| arrange() | 지정한 열 기준으로 정렬합니다. (기본값 오름차순) |
| mutate() | 열을 추가합니다. |
| summarise() | 데이터를 요약합니다.(summarize()로 사용 가능) |
| n() | 기술통계 함수, 데이터 개수를 구합니다. |
| n_distinct() | 기술통계 함수, 중복값을 제거한 데이터 개수를 구합니다. |
| group_by() | 데이터를 그룹화합니다. |
| sample_n() | n개의 샘플을 추출합니다. |
| sample_frac() | n% 비율 샘플을 추출합니다. |
그리고 데이터를 가공하는 과정(데이터 추출, 정렬, 요약, 결합 등)을 실습해보았습니다.
데이터를 재구조화하기 위해 reshape2 패키지도 활용해보았습니다.
| 함수 | 기능 |
| melt() | 데이터의 열을 행으로 바꿉니다. |
| acast() | 데이터의 행을 열로 바꿉니다(벡터, 행렬, 배열로 반환합니다). |
| dcast() | 데이터의 행을 열로 바꿉니다(데이터 프레임으로 반환합니다). |
마지막으로 원시데이터를 정제하기 위해 결측치, 이상치 등을 확인하고 정리하는 것에 대해 공부했습니다.
이번 주 미션은 다음과 같습니다.
| # | 진도 | 기본 미션 | 선택 미션 |
| 5주차 | Chapter 05 | p.244의 확인문제 2번 풀고 인증샷 | p.261 확인문제 4번 풀고 인증샷 |
기본 미션
혼자공부하는 R 데이터분석 p.244 확인문제 2번
2. 225쪽에서 가져온 exdata1 테이블에서 AGE가 30세 이하이면서 Y20_CNT가 10건 이상인 데이터를 exdata2 테이블로 생성하는 코드를 작성하여 결과처럼 출력해보세요. (파이프 연산자를 사용해 보세요.)
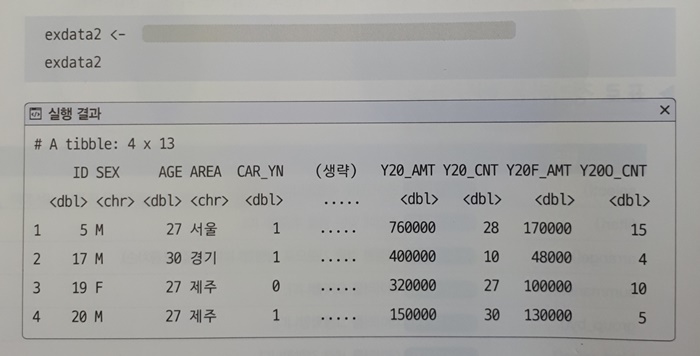
먼저 exdata1 테이블을 만들기 위해서 readxl 라이브러리를 불러오고 read_excel() 함수를 이용하여 다운로드 받은 xlsx 파일을 열었습니다.
>>> library(readxl)
>>> exdata1 <- read_excel("C:/ .... /Sample1.xlsx")
>>> exdata1
문제에서 조건이 AGE가 30세 이하이면서 Y20_CNT가 10건 이상인 데이터를 골라내야 한다고 했으므로 조건은 다음과 같습니다.
AGE <= 30 & Y20_CNT >= 10
주어진 조건에 따라 행들을 추출하는 함수는 filter() 함수입니다.
filter(데이터, 조건문)
아래와 같이 exdata2 테이블을 생성했습니다.
>>> exdata2 <- filter(exdata1, AGE <= 30 & Y20_CNT >= 10)
>>> exdata2

원하는 결과가 제대로 출력된 걸 확인할 수 있었습니다...만 아직 해결하지 못한 문제가 있습니다. 바로 파이프 연산자(%>%)인데요. 파이프 연산자를 활용하여 과제를 해결해보겠습니다.
파이프 연산자를 활용하여 filter() 함수를 사용하려면 아래와 같이 구문을 입력합니다.
데이터 %>% filter(조건문)
이를 이용하여 과제를 다음과 같이 해결하였습니다.
>>> exdata2 <- exdata1 %>% filter(AGE <= 30 & Y20_CNT >= 10)
>>> exdata2

파이프 연산자를 이용해서도 동일한 결과를 만들어 낼 수 있었습니다.
선택 미션
p.261 확인문제 4번
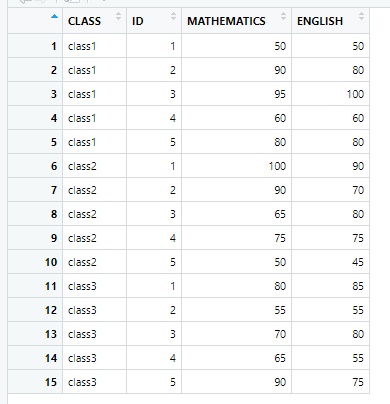
4. 1학년 1반, 2반, 3반 학생 5명씩의 중간고사와 기말고사 성적이 기록된 엑셀 파일을 가져온 후 다음 실행 결과와 같이 반별 수학 점수와 영어 점수를 각각 출력해 보세요.

일단 주어진 데이터를 불러와서 확인하기 위해 첫 세 줄을 입력했습니다.
>>> library(readxl)
>>> middle_mid_exam <- read_excel("C:/ .... /middle_mid_exam.xlsx")
>>> View(middle_mid_exam)
데이터가 어떻게 생겼는지를 확인할 수 있습니다.
일단 실행 결과로 만들 데이터는 과목별로 필요한 열만 선택해야 합니다. select() 함수를 사용하기 위해 dplyr 패키지가 필요합니다.
또한 결과로 만들어낼 데이터는 기존의 데이터와 행과 열이 바뀌어 있습니다. dcast() 함수를 사용하기 위해reshape2 패키지가 필요합니다.
두 패키지를 불러옵니다.
>>> library(dplyr)
>>> library(reshape2)
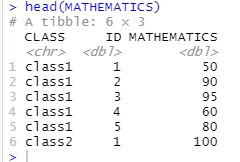
이제 과목별로 원하는 데이터 프레임을 만들어보겠습니다. 먼저 수학(MATHEMATICS) 데이터 테이블을 만들어보겠습니다. 테이블에 ID, CLASS, MATHEMATICS 열만 남기기 위해 select() 함수를 이용했습니다.
>>> MATHEMATICS <- middle_mid_exam %>% select(CLASS, ID, MATHEMATICS)
이렇게 만들어진 테이블을 확인해보기 위해 head() 함수로 살펴보았습니다.
이제 문제에 주어진 형태로 행과 열을 새롭게 정렬해보겠습니다. reshape2 패키지의 dcast() 함수를 이용합니다.
>>> MATHEMATICS <- dcast(MATHEMATICS, ID ~ CLASS)
이렇게 MATHEMATICS 데이터에서 ID열 기준으로 하여 CLASS 값들을 정렬합니다.
그런데 한 가지 아쉬운 점은 문제에서 새롭게 만드는 데이터 세트 이름을 MATHEMATICS로 지정해주었는데, 데이터 세트 안에 이미 MATHEMATICS라는 값(value? column?)이 있어서 조금 헷갈렸습니다.
아니나 다를까? 그래서 인지 아래와 같은 오류 메시지가 나타납니다.
Using MATHEMATICS as value column: use value.var to override.
무시하고 데이터 세트를 출력해보니 결과는 원하는 대로 나타났습니다.
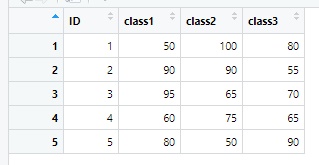
이어서 영어 과목도 완성해보겠습니다. 수학 과목과 방법은 동일합니다. 혹시나 해서 데이터 세트 이름을 열 제목과 다르게 만들어보겠습니다.
>>> ENGLISH_DATA <- middle_mid_exam %>% select(CLASS, ID, ENGLISH)
>>> head(ENGLISH_DATA)
이번에는 CLASS, ID, ENGLISH 열만 남겨두었습니다.
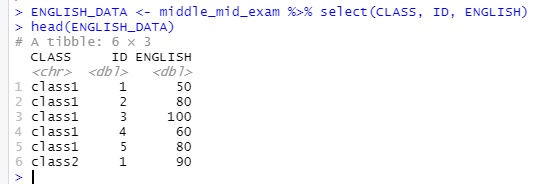
dcast() 함수로 적절히 수정을 해 주었습니다.
>>> ENGLISH_DATA <- dcast(ENGLISH_DATA, ID ~ CLASS)
그랬더니...
여전히 에러메시지는 나타났습니다.

다행히 결과는 잘 나왔습니다.
번외편
dcast() 함수를 사용했는데 나타났던 "use value.var to override." 오류는 도대체 무엇일까?
다른 책을 찾아보았더니 dcast() 함수를 다음과 같이 사용할 수 있는 것 같았습니다.
dcast(ENGLISH_DATA, ID ~ CLASS, value.var = "ENGLISH")
실험을 해 보겠습니다. 아래와 같이 입력하고 결과를 살펴보겠습니다.
ENGLISH_DATA2 <- middle_mid_exam %>% select(CLASS, ID, ENGLISH)
ENGLISH_DATA2 <- dcast(ENGLISH_DATA2, ID ~ CLASS, value.var = "ENGLISH")
View(ENGLISH_DATA2)
이번에는 use value.var to override 오류가 나타나지 않았습니다. 물론 결과도 잘 나왔습니다. 그렇다면...?
단순한 호기심에 아래와 같이 실행을 해 보았습니다.
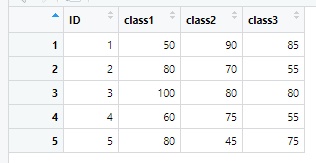
>>> ENGLISH_DATA3 <- dcast(middle_mid_exam, ID ~ CLASS, value.var = "ENGLISH")
>>> View(ENGLISH_DATA3)
원본 데이터를 다시 확인해보겠습니다.
이렇게 생겼던 데이터를 이전에는 select() 함수를 사용하여 CLASS, ID, ENGLISH 열만 남겨두었습니다.
그런 다음 dcast() 함수를 사용하여 ID를 기준 열로 하고 CLASS 별(class1, class2, class3)로 ENGLISH의 값을 대입하도록 테이블을 만들었습니다. 그 때 사용한 구문이 아래와 같습니다.
>>> ENGLISH_DATA <- dcast(ENGLISH_DATA, ID ~ CLASS)
이 구문에는 ENGLISH_DATA에서 ID를 기준으로 하고 CLASS별로 정렬(ID ~ CLASS)하라는 내용은 있지만 어떤 값을 넣으라는 이야기는 없습니다. 단지 사용하지 않았던 열(ENGLISH)을 value 값으로 넣었던 것 같습니다. (Using ENGLISH as value column이 그런 뜻?)
그래서 실험삼아 원본 데이터를 이용하여 value.var = "ENGLISH" 옵션을 넣어보았습니다.
>>> ENGLISH_DATA3 <- dcast(middle_mid_exam, ID ~ CLASS, value.var = "ENGLISH")
>>> View(ENGLISH_DATA3)
원본데이터에서 ID를 기준 열로 하고 CLASS를 변환 열로 만들 경우 ENGLISH 열과 MATHEMATICS 열이 남습니다. 그래서 value.var = "ENGLISH" 를 넣어서 ENGLISH 열을 value로 하겠다고 선언한 것입니다.
물론 이렇게 했더닌 결과는 이전에 원했던 결과와 동일하게 나타났습니다.
마지막 검증으로 아래와 같이 입력도 해 보았습니다.
>>> MATHEMATICS_DATA <- dcast(middle_mid_exam, ID ~ CLASS, value.var = "MATHEMATICS")
>>> View(MATHEMATICS_DATA)
결과는!!!
MATHEMATICS 테이블이 제대로 출력되었습니다!!!
뭔가 제대로 이해를 하고 있는 것 같아 뿌듯합니다!!
혹시나 해서 아래와 같이도 입력해보았습니다.
>>> DATA_TEST <- dcast(middle_mid_exam, ID ~ CLASS)
Using ENGLISH as value column: use value.var to override.
원본 데이터에 value.var 옵션을 사용하지 않은 경우입니다. 이럴 때는 MATHEMATICS 열과 ENGLISH 열이 남는데 ENGLISH 열을 value column으로 사용하겠다는 메시지로 드디어 읽혀집니다. 결과도 ENGLISH 데이터 프레임이 생성되었습니다.
혼공학습단 8기, 방학이 지나고 5주차 학습도 마무리하였습니다.
이제 한 주가 남았네요. 5주라는 시간이 후딱 지나간 것 같습니다.
마지막까지 열심히 공부하고 잘 마무리 하였으면 좋겠습니다!!! 모두 모두 화이팅!!

혼자 공부하는 R 데이터 분석 - YES24
혼자 해도 충분하다! 1:1 과외하듯 배우는 R 데이터 분석 자습서이 책은 독학으로 R 데이터 분석을 배우는 입문자가 ‘꼭 필요한 내용을 제대로’ 학습할 수 있도록 구성했다. ‘무엇을’, ‘어떻
www.yes24.com




댓글