[스터디 2일차] 데이터 분석을 위한 준비 (데이터 가공) :: 모두의 데이터 분석 with 파이썬

파이썬을 이용한 데이터 분석 개인 스터디 두 번째 입니다.
교재는 "길벗" 출판사에서 나온 "모두의 데이터 분석 with 파이썬"입니다.
서울의 기온 데이터 분석하기
오늘은 기상청 기상자료개방포털에서 서울의 기온 데이터를 다운로드 받아서 분석을 진행하려고 합니다.
기상자료개방포털
data.kma.go.kr
링크를 클릭해서 기상자료개방포털에 접속합니다.
CSV 파일 다운로드
기상청 기상자료개방포털에 접속했습니다.

[ 기후통계분석 ] 메뉴를 클릭해서 통계 데이터를 다운로드 받아봅시다.

기간을 1904년 1월 1일(제일 앞이더라구요, 일제시대 데이터 부터 있다니....)부터 실습을 진행한 날짜(2020년 3월 7일)로 셋팅하고 [ 검색 ] 버튼을 눌렀습니다. 시간이 잠시 흐르고 아래에 빨간 그래프가 나타납니다. 검색 버튼 아래쪽에 있는 [ CSV 다운로드 ] 버튼을 누르자 csv 파일이 다운로드 되었습니다.
참고로 위 사진에서 가운데에 살짝 빈 부분이 있네요(초록색 사각형 부분). 이에 대해서는 잠시 후에 다시 확인을 해보겠습니다.
CSV 파일 확인 및 가공
다운로드한 csv 파일을 엑셀 프로그램으로 열어봅니다. 저는 엑셀 프로그램 대신 구글에서 제공하는 스프레드시트(https://docs.google.com/spreadsheets/)에서 열었습니다.

데이터 분석에 불필요한 행들(1~7열)이 보입니다. 데이터에 대한 기본 정보들인 것 같은데, 실제 데이터 분석에서는 사용되지 않습니다. 그래서 삭제! (데이터만 삭제하는 것이 아니라 행을 삭제합니다.)
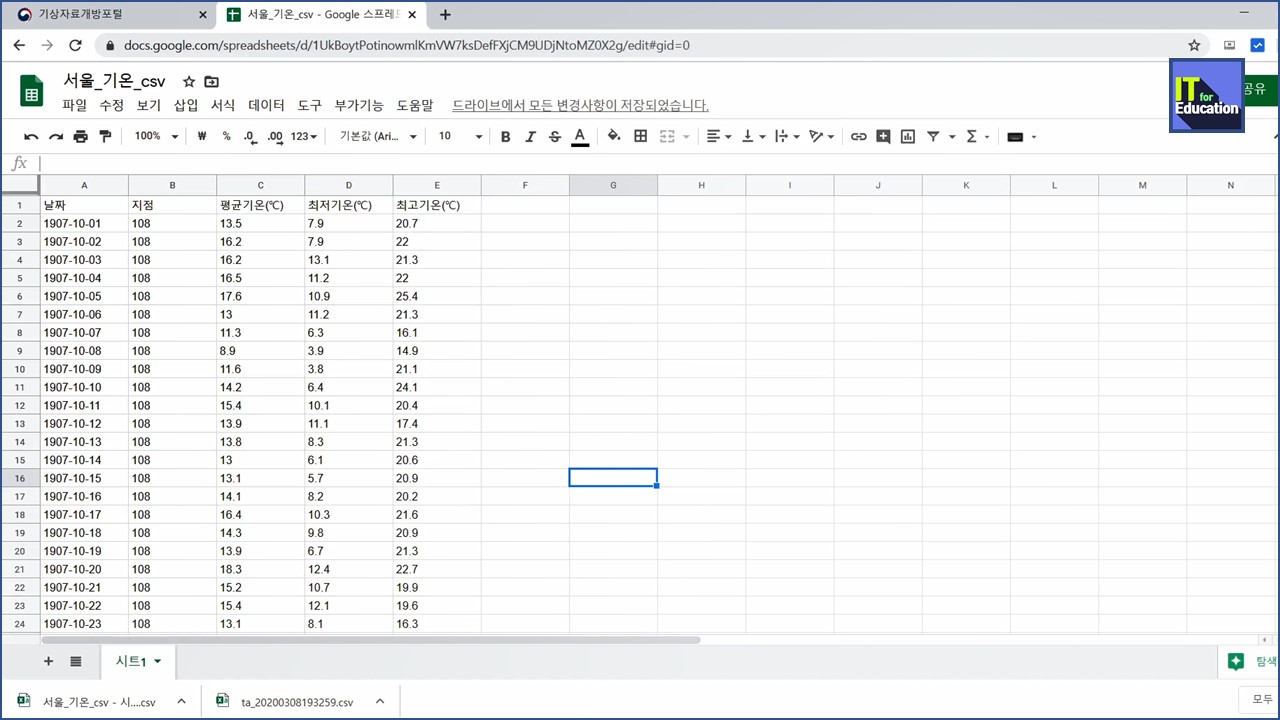
분석하기 위한 데이터 준비가 끝났습니다. CSV 파일로 저장(내보내기)을 하면 준비 끝!
공공데이터들을 인터넷에서 이렇게 얻을 수 있다는 것이 신기하네요.
본격적인 데이터 분석 시작하기
주피터 노트북 실행하기
지난 번에 아나콘다를 설치(https://it4edu.tistory.com/55) 했었는데요. 이때 함께 설치된 주피터 노트북을 실행합니다.
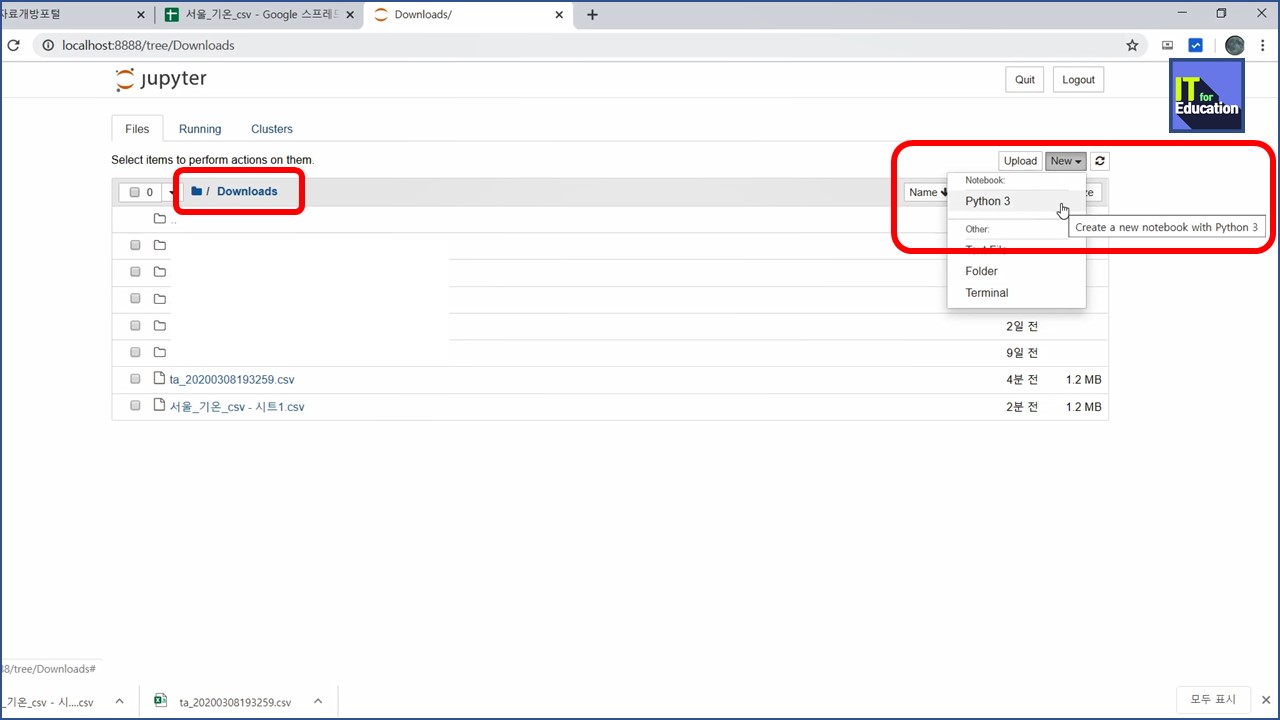
브라우저가 실행됩니다. Downloads 폴더를 선택하고, 오른쪽에 New 버튼을 눌러서 Python 3를 실행하면 새로운 노트북이 생성됩니다.
문서 이름을 알아보기 쉽게 변경합니다. 그리고 아래와 같이 코드를 입력했습니다.
import csv
f = open('seoul.csv', 'r', encoding='cp949')
data = csv.reader(f, delimiter=',')
print(data)
f.close()
(여기부터는 살짝 뇌피셜 입니다. 저...는 파이썬을 잘 모르거.....든...요....)
첫 줄은 csv를 불러오겠다는 이야기인 것 같고...
두 번째 줄은 seoul.csv 파일을 cp949 형식으로 인코딩해서 f라는 곳으로 열겠다는 것 같고...
세 번째 줄은 data 라는 곳에 seoul.csv 파일을 읽어드리고
네 번째 줄은 data 를 출력하고
다섯 번째 줄은 아까 열었던 f를 닫으라는 이야기 같습니다.....
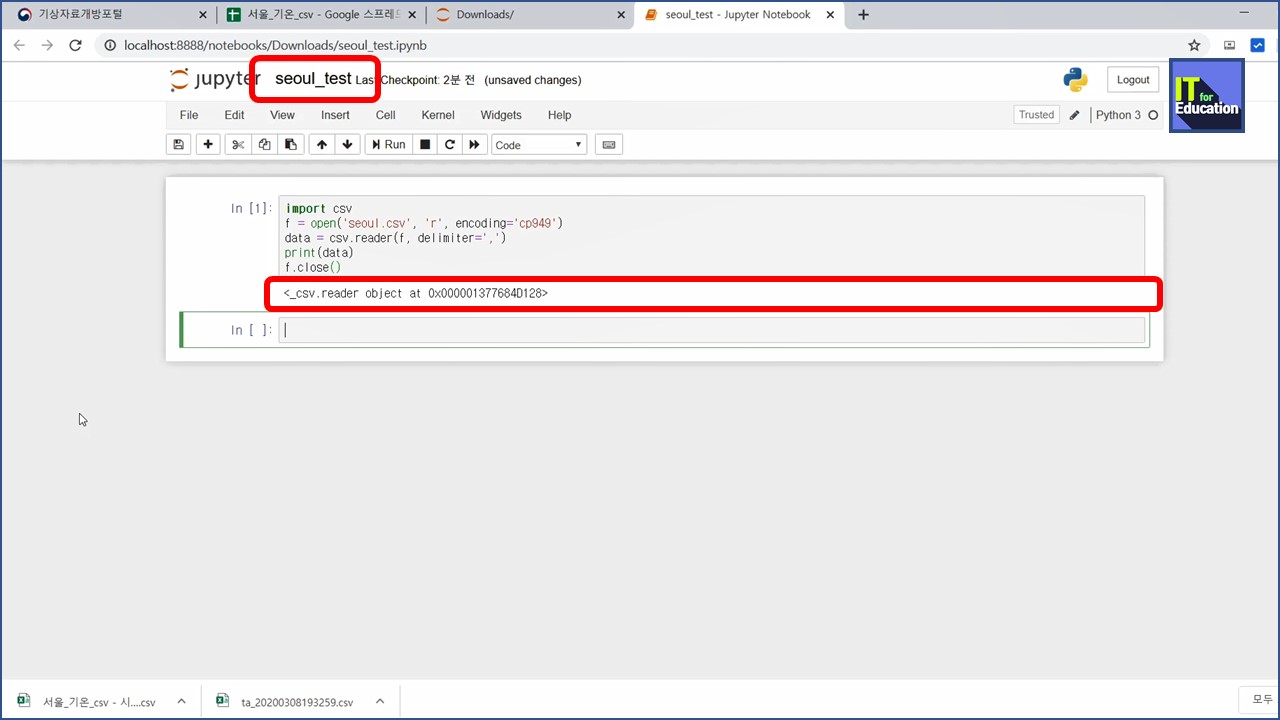
실행 버튼을 눌렀더니 실행 결과가 나왔습니다.
_csv.reader object at 어쩌구 저쩌구...
아직 큰 재미는 없네요.
코드 중간에 아래 코드를 넣었습니다.
for row in data :
print(row)
for 는 반복문인 것 같고, data라는 곳에서 row 마다... 이니.. 행 단위로 뭔가를 하는 듯 합니다.
print는 출력이고...
과연 결과가 계상한대로 나올까요?
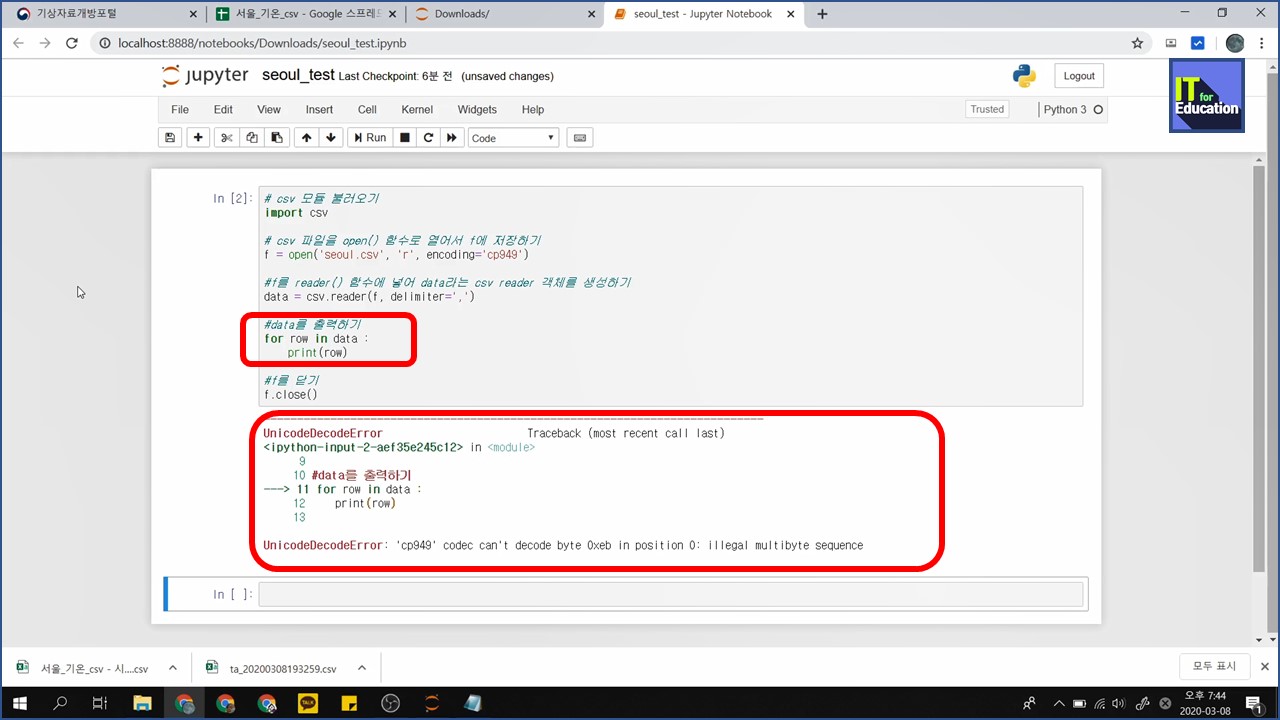
어랏... 큰 문제가 생겼네요..
UnicodeDecodeError: 'cp949' codec can't decode byte 0xeb in position 0: illegal multibyte sequence
무슨 말일까? 구글링을 찾아서 살짝 해법을 찾았습니다.
encoding을 cp949에서 utf-8 로 바꾸면 해결이 되더라구요. (한글 인코딩 방식 때문에 그런것 같습니다.)
실제로 utf, utf8, utf-8 다 작동하는 것 같더라구요.

인코딩 옵션을 수정하고 실행했더니 결과가 나옵니다.
정말로 행 단위로 데이터들이 주루룩 나타납니다. 와우!!

결과가 제대로 나왔는지 스크롤을 내리다 보니 이상한 곳들이 있네요. 1950년 9월 1일 부터 자료가 표시되지 않네요. 아마도 한국전쟁 당시라서 데이터가 수집되지 못했던 게 아닌가 싶습니다. 앞에 그래프에서 중간에 비어있는 구간(초록색 네모)이 이 구간인 듯 합니다.
헤더 저장하기
헤더는 데이터의 첫 번째 줄에 위치하여 두 번째 줄부터 나타나는 데이터의 속성을 설명합니다. 그래서 매우 중요한 데이터이긴 한데, 실제 데이터 분석에서는 필요하지 않습니다. 헤더를 별도로 저장하기 위한 함수가 있는데 바로 next() 함수를 사용할 수 있습니다.
이 함수가 어떤 것인지 알아보기 위해 코드에 다음 내용을 추가했습니다.
header = next(data)
print(header)

출력을 해 보았더니 정말 첫 행(헤더)만 출력이 되었습니다. 그런데 왜 함수 이름이 next() 일까요? header().. 이런 이름이 아니고요...?
next() 함수는 첫 번째 데이터 행을 읽어오면서 데이터의 탐색 위치를 다음으로 이동시키는 명령이라고 합니다.
그랬군요... 전체적으로 완성된 코드를 입력해 보았습니다.
# csv 모듈 불러오기
import csv
# csv 파일을 open() 함수로 열어서 f에 저장하기
f = open('seoul.csv', 'r', encoding='utf-8')
#f를 reader() 함수에 넣어 data라는 csv reader 객체를 생성하기
data = csv.reader(f, delimiter=',')
#header 저장하기
header = next(data)
#data를 출력하기
for row in data :
print(row)
#f를 닫기
f.close()
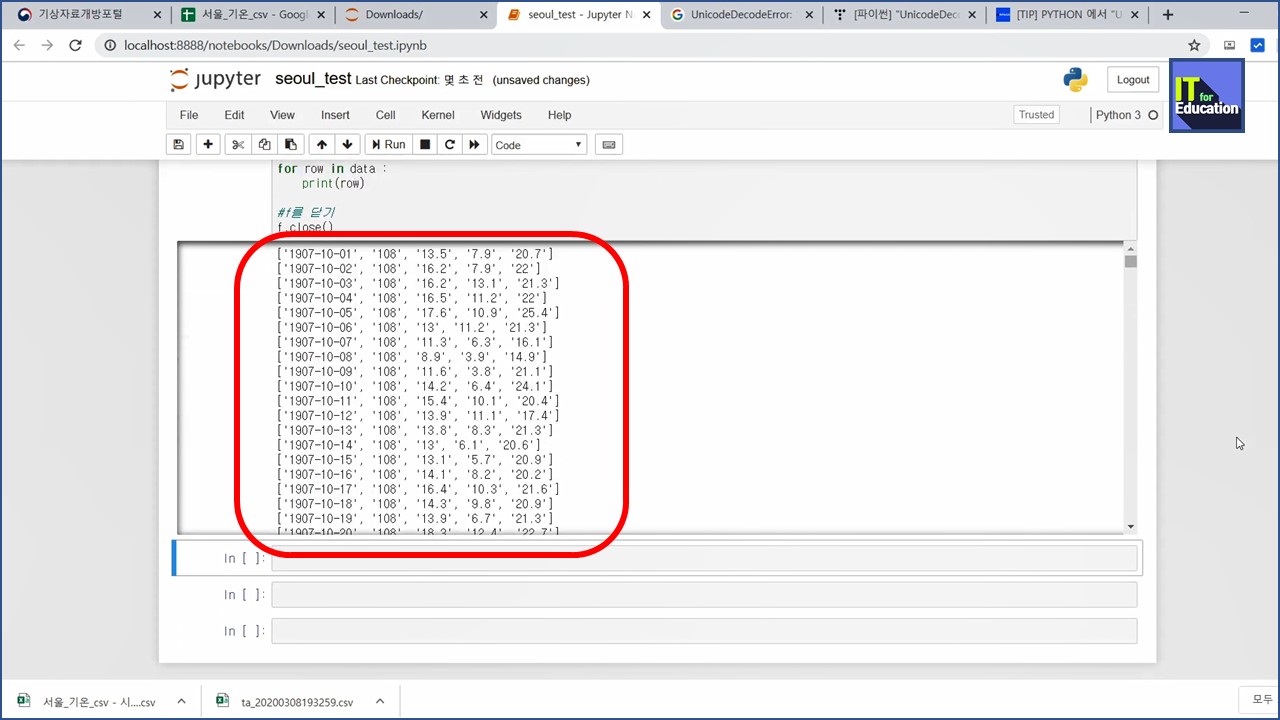
헤더가 빠진 날 데이터들만 행별로 쭈~욱 출력되었습니다.
이렇게 기초 데이터 가공과 출력까지 해 보았습니다. 다음 스터디도 기대가 되네요. 뭔가 재미있어요^^
(정리하는 건 좀 귀찮고 어렵긴 하네요...ㄷㄷㄷ)
'개인 공부 > 데이터 분석' 카테고리의 다른 글
| [스터디 1일차 도약] 아나콘다 설치 시 제공되는 라이브러리들 :: 모두의 데이터 분석 with 파이썬 (0) | 2020.02.21 |
|---|---|
| [스터디 1일차] 데이터 분석 환경 만들기 (아나콘다 설치) :: 모두의 데이터 분석 with 파이썬 (1) | 2020.02.20 |


댓글