반응형
[혼공단9기] 혼공학습단 9기 5주차 - SQL 인덱스 개념, 내부 작동, 실제 사용(feat. 혼자 공부하는 SQL, 혼공S, 혼공스)

이번 주 스터디 내용 요약
06-1. 인덱스 개념을 파악하자
- 인덱스(index)는 데이터를 빠르게 찾을 수 있도록 도와주는 도구
- 클러스터형 인덱스(Clustered Index) : 기본 키로 지정하면 자동 생성, 테이블에 1개만 가능, 자동 정렬
- 보조 인덱스(Secondary Index) : 고유 키로 지정하면 자동 생성, 여러 개 생성 가능, 자동 정렬 안됨
인덱스의 개념
인덱스의 문제점
- 필요 없는 인덱스를 만들면 데이터베이스가 차지하는 공간만 더 늘어나고, 인덱스틀 이용해서 데이터를 찾는 것이 전체 테이블을 찾아보는 것보다 느려질 수 있음.
인덱스의 장점
- SELECT 문으로 검색하는 속도가 매우 빨라짐
- 컴퓨터의 부담이 줄어들어 결국 전체 시스템의 성능이 향상됨
인덱스의 단점
- 인덱스도 공간을 차지해서 데이터베이스 안에 추가적인 공간이 필요
- 처음에 인덱스를 만드는 데 시간이 오래 걸릴 수 있음
인덱스의 종류
클러스터형 인덱스: 자동으로 정렬되는 인덱스
- 기본 키(PRIMARY KEY)로 지정하면 자동 생성
- 테이블에 1개만 생성
- 기본 키 열을 기준으로 자동 정렬
보조 인덱스: 정렬되지 않는 인덱스
- 고유 키(UNIQUE)로 지정하면 자동 생성
- 테이블에 여러 개 설정 가능
- 데이터의 순서는 변경되지 않음
06-2. 인덱스의 내부 작동
- 인덱스는 내부적으로 균형 트리(Balanced tree, B-tree), 즉 나무를 거꾸로 표현한 자료 구조로 구성됨
- 노드(node)는 트리 구조에서 데이터가 저장되는 공간, MySQL에서는 페이지(Page)라고 부름
- 페이지 분할: 데이터를 입력할 때, 입력할 페이지에 공간이 없어서 2개 페이지로 데이터가 나눠지는 것
- 인덱스 검색: 클러스터형 또는 보조 인덱스를 이용해서 데이터를 검색하는 것
06-3. 인덱스의 실제 사용
인덱스 생성
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC]
인덱스 제거
DROP INDEX 인덱스_이름 ON 테이블_이름
| # | 진도 | 기본 미션 | 선택 미션 |
| 5주차 (2/6 ~ 2/12) |
Chapter 06 | p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기 | 인덱스 생성, 제거하는 기본 형식 작성하기 |
기본 미션
p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기
일단 자료실에서 제공된 SQL을 실행해서 market_db를 만들었습니다.
USE market_db;
SELECT * FROM member;

SHOW INDEX 문으로 member에 어떤 인덱스가 설정되어 있는지를 확인합니다.
SHOW INDEX FROM member;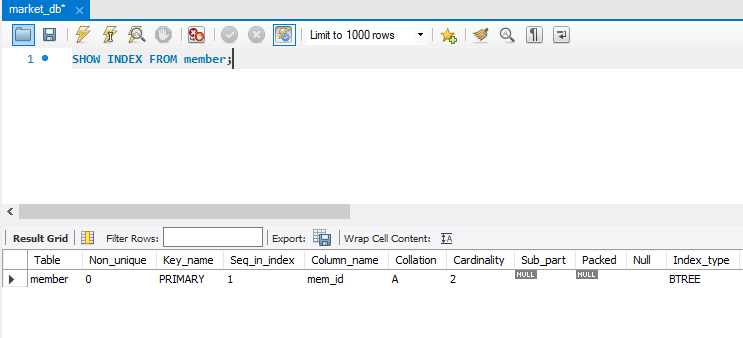
- Non_unique가 0이므로 unique(고유)하다는 뜻
- Key_name이 PRIMARY이므로 클러스터형 인덱스라는 뜻
선택 미션
인덱스 생성, 제거하는 기본 형식 작성하기
인덱스 생성
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC]
인덱스 제거
DROP INDEX 인덱스_이름 ON 테이블_이름https://www.youtube.com/watch?v=QkGz9Am51Nc
이번에도 구독과 좋아요, 알림설정은 부탁안해요...ㅎㅎ 구걸해요...
혼자 공부하는 SQL - YES24
혼자 해도 충분하다! 1:1 과외하듯 배우는 데이터베이스 자습서(MySQL Community 8.0 지원)이 책은 아무런 사전 지식 없는 입문자가 ‘꼭 필요한 내용을 제대로’ 학습할 수 있도록 구성했다. ‘무엇을
www.yes24.com
반응형




댓글